GC Theory – mark&sweep algorithm
Mark&sweep was already mentioned in the previous posts. It is a cornerstone of all the marking algorithms, and is used as a backup for cyclic data structures in the ref counting. The time has come then to take a deeper look at it.
Basics of mark&sweep
To remind us what we’re discussing here – mark&sweep GC was first introduced in the 1960 by McCarthy. It consists of two separate parts – marking – where all the objects are identified as used/unused, and sweep – when they’re just removed from the memory. As the authors say – this type of algorithm is indirect collection algorithm. In other words – it does not find garbage. It rather finds all live objects, and treat everything else as garbage.
What must be said, is that every time a mutator (so our running application) tries to allocate a memory, and there’s none, a collector is called to free some of it. For the time being we assume, that at this stage, all the mutator threads are paused, and stop-the-world happens (no mutator threads running). Very simplistic pseudocode of mark can be found below (it comes from the second book):
New():
ref ← allocate()
if ref = null /∗ Heap is full ∗/
collect()
ref ← allocate()
if ref = null /∗ Heap is still full ∗/
error "Out of memory"
return ref
atomic collect(): // Pay attention to the 'atomic' - it means 'stop-the-world'
markFromRoots() // It traverses the whole graph starting from Roots
sweep(HeapStart, HeapEnd)
markFromRoots():
initialise(worklist)
for each fld in Roots
ref ← *fld
if ref != null && not isMarked(ref)
setMarked(ref)
add(worklist, ref)
mark()
initialise(worklist):
worklist ← empty
mark():
while not isEmpty(worklist)
ref ← remove(worklist) /∗ ref is marked ∗/
for each fld in Pointers(ref)
child ← *fld
if child != null && not isMarked(child)
setMarked(child)
add(worklist, child)
In general the algorithm runs as long, as the worklist is not empty. As we skip the objects that are already marked or do not contain pointers, worklist won’t grow forever, and eventually will become empty. Then the second part starts – sweeping.
sweep(start, end):
scan ← start
while scan < end
if isMarked(scan)
unsetMarked(scan)
else free(scan)
scan ← nextObject
It may look simple, but it raises a couple of issues that we must be aware of. First – traversing the heap freeing the memory can be time-consuming, depending on its size. Second issue is – when to reset the mark bit (the information if the object is marked/unmarked) – during sweeping or maybe at the beginning of the next mark phase. Last thing that authors mention is memory/heap layout. We must be sure about two things – that the heap won’t become so fragmented in time, that it won’t be possible for GC to actually allocate new objects on it (or just running GC too often to achieve that), and also to make sure that all the garbage is reachable (due to memory padding constraints, etc.). This topic will be discussed in the future posts too.
Tricolour abstraction
The process described above implies, that there will be objects in the graph that were not visited by GC, the ones marked but with not yet visited children, and objects that were visited and their children a swell. In order to easily differentiate these objects a concept called tricolour abstraction emerged (authored by Dijkstra).
Under the tricolour abstraction, tracing collection partitions the object graph into black (presumed live) and white (possibly dead) objects. Initially, every node is white; when a node is first encountered during tracing it is coloured grey; when it has been scanned and its children identified, it is shaded black. Conceptually, an object is black if the collector has finished processing it, and grey if the collector knows about it but has not yet finished processing it (or needs to process it again).
Similarly, this abstraction can be used for fields or even roots. It provides a handy naming when discussing tracing algorithms. Below animation from Wikipedia should be helpful in visualising it.
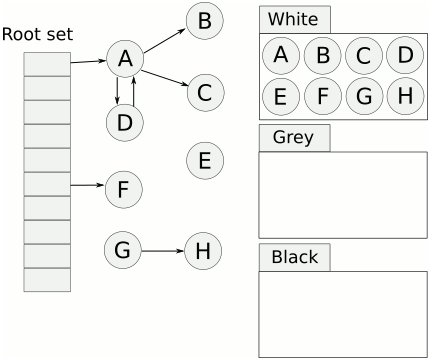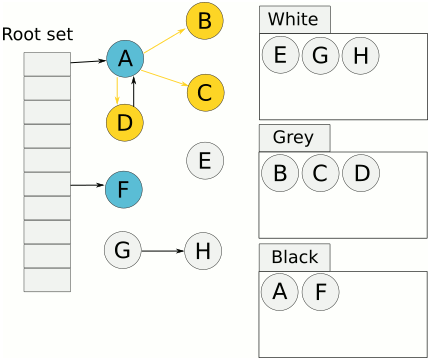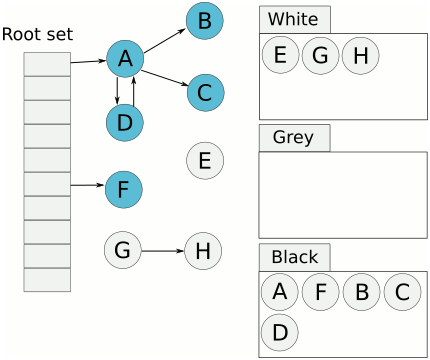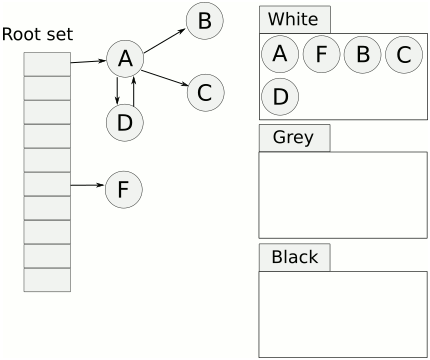
How to deal with unbound nature of mark&sweep?
In the first article about GC, a simple example of mark&sweep was given.
mark_sweep() =
for R in Roots
mark(R) // mark objects for removal
sweep() // clear the memory
if free_pool is empty // error handling
abort "Memory exhausted"
The problem here, is its recursive nature, which can be expensive, and also can lead to simple stack overflow, if there’s too many objects to mark. What is more, we need to pay attention to the possible cost of the marking – the depth of the stack is important here. Below we tackle these problems one by one.
Explicit recursion
Safer way to deal with recursion is to use auxiliary stack, which is limited in size, and some precautions can be built into it. Authors of the books provide this algorithm, as an example usage of such auxiliary stack. It is only for demonstration purposes, we don’t deal with possible overflow here!
mark_heap() {
mark_stack = empty
for R in Roots
mark_bit(*R) = marked
push(*R, mark_stack)
mark()
}
mark() {
while mark_stack != empty
N = pop(mark_stack)
for M in Children(N)
if mark_bit(*M) == unmarked
mark_bit(*M) = marked
if not atom(*M) // atom means 'not holding a pointer/reference'
push(*M, mark_stack)
}
Stack depth
In the ‘Garbage Collection’ book (the first one), there are two pages dedicated to explaining the concept, however in the second one this subject is not even mentioned. To be honest I am not surprised by this, because the only key takeout that I could understand, was that there’s a Boehm-Demers-Weiser GC. This GC solution (being a type of conservative GC) will be discussed in a separate chapter. That’s it. Keep reading.
Stack overflow
Using auxiliary stack is a great solution to prevent stack overflow. The naive idea, would be to check for the possibility of it with every push operation. More robust solution would be to count the amount of pointers that the node (meaning the element in the auxiliary stack) has, and perform a check then (so only once with new item being iterated over in the main loop). The very secure option (if the memory architecture allows it), is to use guard page, which is the last part of stack. The beauty of it is, that it is read-only. Any attempt to write it, will result in an exception. It’s easier to handle a specific type of exception, rather than make sure to check the count of pointers/free memory left.
In general there are two generic solutions to the problem, proposed by Knuth and Kurokawa. The first one is based on two-phase marking phase. Let’s start with the quote:
Knuth handles overflow by treating the marking stack circularly, stacking pointers to nodes modulo h, where h is the fixed size of the stack. This means that older branch- point information on the stack is overwritten when the stack index grows larger than h. Consequently, the stack may become empty before the marking process is complete as the live graph below a node whose pointer on the mark stack has been overwritten may not have been marked.
In this situation, if the auxiliary stack is 3, and I put there three objects – A, B and C, when the fourth object goes there – D, we should have an overflow. However, we just discard object A, and continue our work. When the whole auxiliary stack is emptied, we go again through the heap, and we check for the objects that are marked, but have unmarked children. These are probably the ones that were discarded (so A from our above example), and we restart the marking there.
Kurokawa algorithm is mentioned only in the context of shared nodes, and is said to need a backup of more safe algorithm. In short when overflow occurs, a stacked node checking is fired, resulting in two possible behaviours:
- if no child is unmarked – just clear the slot
- if ONLY ONE child is unmarked – mark it, and then search for a descendant with 2 or more unmarked children. If there’s no such object – the stack slot is emptied, if it is – it replaces the existing element.
Pointer reversal
The technique of pointer reversal was suggested (separately by Deutsch and Shorr-Waite) as w way to hide auxiliary stack in the already existing heap objects. The idea is to reuse existing nodes that are being marked, to hold information about the marking state. The best way to describe it is this SO answer. I won’t even try to describe the algorithm here, as it requires a lot of drawing. What is more – it’s not mentioned in the second book, and even in the first one it clearly says, that the performance of the algorithm is poor compared to regular auxiliary stack solutions. Graphic explanation can be found on this PDF, starting from page 3.
Bitmap marking
So far we’ve looked at the situation, where marking bit was kept in the object itself. However, that can cause a significant memory usage, especially if a lot of small objects is generated. One way of dealing with it is to use bitmap marking, where information about marked objects is kept in the separate data structure, namely – bitmap. The idea is simple – every bit in this data structure corresponds to the beginning of the object on the heap. Or in other words – to the memory address that may contain it.
Why are bitmaps so nice? Because they avoid potential race conditions and/or page faults. As I’ve written above – bitmap is a separate data structure, which is usually kept in the RAM directly (due to its small size). Therefore, we don’t perform any kind of write instructions in the objects on the heap (which happens when the mark bit is kept in the header). With that, there’s less chance to cause a page fault, or to discard values from the cache.
The problem with them is only one – mapping between the map, and an actual address in the memory can take some time. Depending on the approach (block maps for example), it can be over 10 different instructions executed to calculate an actual address.
Lazy sweeping
So far we’ve concentrated on the marking phase. However, as the name says, we got two phases in the mark&sweep. Now it’s time to deal with the sweeping, where some additional optimisations can be done. To start with – previous section described bitmaps, as a separate data structure holding info whether an object is marked or not. We’ve mentioned that due to its size, it is possible to keep it in RAM, which reduces the problems with possible page faults.
What is more – in the modern hardware, there’s a lot of support on the hardware level, that makes the software faster. One example would be memory prefetching, which is a process of reading data from slower storage (RAM in this example), and putting it to faster one (CPU cache for example). Alternatively, it can also mean that the hardware allocates a continuous piece of memory, when the allocator is called. Therefore, during marking phase, there’s a big chance that a whole block of memory would be marked and then freed, avoiding fragmentation. Modern architectures are quite good at this.
Allocating memory in blocks/continuous pieces is one thing. Second thing is the sweeping process itself. No matter what’s the technique used for marking, actual sweeping can be executed parallel to running application (which is called mutator). We can safely assume, that if the object is marked as not used, it can be safely deleted, as there’s no way for the mutator to access this data. Parallelism will be discussed in the next chapters of the book (using separate threads to do that). Right now, two algorithms are presented, that enable us to postpone the sweeping until the memory is actually needed. That kind of algorithms are called lazy sweeping. We will start with the one described in detail in the blue book – Hughes’ algorithm.
allocate() =
while sweep < heap_top // continue sweeping
if mark_bit(sweep) == marked
mark_bit(sweep) = unmarked
sweep = sweep + size(sweep)
else
result = sweep
sweep - sweep + size(sweep)
return result
mark_heap() // done when heap is full
sweep = Heap_bottom
while sweep < Heap_top
if mark_bit(sweep) == marked // this piece is the same as above
mark_bit(sweep) = unmarked
sweep = sweep + size(sweep)
else
result = sweep
sweep - sweep + size(sweep)
return result
abort "Memory exhausted"
However, this algorithm works great, if we’re operating with the bit mark kept in the nodes. When information about marking is kept in the bitmap, it is not that simple, as updating every single bit in it will be costly, and it’s usually more efficient to update bits in word, or even a couple of them at the same time. For the sake of completeness – a direct quote:
Nodes reclaimed by the lazy sweep must be saved somewhere, either in a free-list or in a fixed-size vector. The Boehm-Demers-Weiser conservative collector for C and C++ adopts the former approach whilst Zorn’s generational mark-sweep collector for List adopts the latter.
As these two are not presented in the second book, I’m assuming that they did not survive the time trial. To finish this subchapter, I’m pasting a code example with the block-oriented lazy sweeper, from the second book.
atomic collect():
markFromRoots()
for each block in Blocks
if not isMarked(block) /∗ no objects marked in this block? ∗/
add(blockAllocator, block) /∗ return block to block allocator ∗/
else
add(reclaimList, block) /∗ queue block for lazy sweeping ∗/
atomic allocate(sz):
result ← remove(sz) /∗ allocate from size class for sz ∗/
if result = null /∗ if no free slots for this size... ∗/
lazySweep(sz) /∗ sweep a little ∗/
result ← remove(sz)
return result /∗ if still null, collect ∗/
lazySweep(sz):
repeat
block ← nextBlock(reclaimList, sz)
if block != null
sweep(start(block), end(block))
if spaceFound(block)
return
until block = null /∗ reclaim list for this size class is empty ∗/
allocSlow(sz) /∗ get an empty block ∗/
allocSlow(sz): /∗ allocation slow path ∗/
block ← allocateBlock() /∗ from the block allocator ∗/
if block != null
initialise(block, sz)
And a direct quote:
It is common for allocators to place objects of the same size class into a block [..]. Each size class will haveone or more current blocks from which it can allocate and a reclaim list of blocks not yet swept. As usual the collector will mark all live objects in the heap, but instead of eagerly sweeping the whole heap, collect will simply return any completely empty blocks to the block level allocator (line 5). All other blocks are added to the reclaim queue for their size class. Once the stop-the-world phase of the collection cycle is complete, the mutators are restarted.
The allocate method first attempts to acquire a free slot of the required size from an appropriate size class [..]. If that fails, the lazy sweeper is called to sweep one or more remaining blocks of this size class, but only until the request can be satisfied (line 12). However, it may be the case that no blocks remain to be swept or that none of the blocks swept contained any free slots. In this case, the sweeper attempts to acquire a whole fresh block from a lower level, block allocator. This fresh block is initialised by setting up its metadata — for example, threading a free-list through its slots or creating a mark byte map. However, if no fresh blocks are available, the collector must be called.
SOURCES:
- ‘Garbage Collection. Algorithms for automatic dynamic memory management.’ by
Jones&Lins, chapter 3 - ‘The Garbage Collection Handbook.’ by Jones&Hoskings&Moss, chapter 5
- Conference talk about basics of GC algorithms, which is coming from this blog post
- Presentation for GC class
- Tri-colour abstraction and bitmap marking article
- Lecture about mark&sweep slides

Leave a Reply
You must be logged in to post a comment.